

Decoupled DiLoCo: How Google Is Enabling Multi-Region, Distributed LLM Pretraining
An overview of Google’s new multi-region, distributed AI training methodology and its practical impact


Large-scale LLM pretraining is a notoriously complex and resource-intensive process. Training these models can involve up to hundreds of thousands of AI accelerators being colocated. This physical requirement ensures high-bandwidth cabling can connect these accelerators, enabling low-latency communication between them.
Datacenters are built to meet these requirements and provide the necessary power, cooling, housing, and more for these massive compute clusters. Companies go to great efforts to build large datacenters and even campuses of datacenters to colocate their compute.
Google DeepMind and Google Research recently published a paper on Decoupled DiLoCo. This is a training regime designed to make multi-region distributed LLM pretraining more feasible. It reduces communication frequency and removes lock-step synchronization so training progress is not globally blocked by stragglers, failures, or slow links.
DiLoCo reduces communication by synchronizing via an outer optimizer every H steps instead of every step. Decoupled DiLoCo goes further by making synchronization asynchronous and quorum-based, and by using fragmented, scheduled updates to smooth bandwidth demand.
Multi-region, distributed LLM pretraining could potentially mean:
Faster training due to decreased wall-time.
Greater reliability as training doesn’t have to wait on stragglers or failed processes.
Greater goodput (time spent doing meaningful work) because accelerators continue working without waiting, allowing wider distribution.
Massive-scale training as training processes can reliably span multiple areas instead of physically relying on a single datacenter or closely situated datacenters within the same campus.
Reduced training costs due to the factors above.
Google has empirically shown Decoupled DiLoCo can work by training up to a 12B-parameter LLM using the process without sacrificing model quality (in the studied settings). Below, I’ll go over how this process works and what it means practically.
Executive Summary/tl;dr:
LLM pretraining takes place at massive scale and requires many resources.
Multi-region training is especially hard because step-synchronous communication amplifies latency, stragglers, and failures into idle time.
Decoupled DiLoCo improves robustness and wall-clock speed in these settings by combining quorum-based asynchronous syncing with low-frequency outer updates and fragment scheduling.
Google reports improved robustness and comparable downstream quality in the studied settings.
Practical implication: Higher goodput and better ability to use imperfect, hard-to-pool compute capacity for large-scale training.
What makes colocation a necessity?
Before we understand Decoupled DiLoCo, we first need to understand the limitations of distributed training.
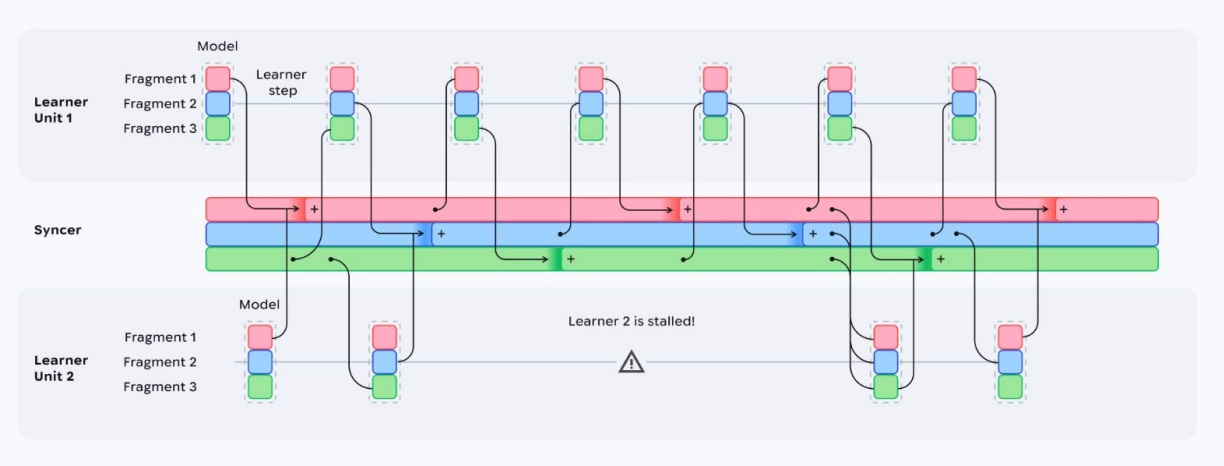
Distributed training is simply training across multiple AI accelerators. This distributes the training job to multiple parallel compute units. Each compute unit has access to specific data. To reconcile the work done across these units, information about that work must be sent to a centralized process, where separate work across accelerators can be combined into model updates. These updates are sent back to the accelerators for further training.
In many common training setups, this reconciliation happens at step boundaries via synchronized communication (e.g., collectives that effectively act like a global barrier). If one learner is slow or fails, the whole step can stall, turning “rare events” into substantial idle time at scale.
In datacenters, the connections between learners and the latency in communication are much lower, making these types of issues much less noticeable. The infrastructure is also much more robust in dealing with errors and stragglers.
Across a WAN (wide area network), this same approach often isn’t feasible. The higher latency means more time spent waiting. The distributed infrastructure can also be less predictable, making it more prone to errors and stragglers.
Thus, colocation provides a much more robust and efficient setup for a process that is already resource-intensive and slow. The sacrifices that come with distributed training make it a much less desirable option.
Figure 1 from the Decoupled DiLoCo announcement showing the benefit of decoupled training.
How does Decoupled DiLoCo fix this?
Decoupled DiLoCo addresses the challenges of WAN / multi-region training by combining:
Low-frequency outer updates (DiLoCo): Reconcile every H steps to reduce communication frequency.
Decoupling and quorum: A syncer can proceed with updates using K-of-M learners rather than waiting for everyone, so stragglers/failures don’t become global stalls.
Fragmented, scheduled syncing: Update only parts of the model at a time on a schedule, smoothing communication demand and making asynchrony more manageable.
DiLoCo (Distributed Low-Communication) uses a variant of federated averaging to enable model updates every H steps. It introduces two separate optimizers, an “inside optimization” that takes place locally at the learner, and an “outer optimization” that takes place centrally. Learners can spend multiple steps optimizing locally before optimizing centrally.
To better understand this process, check out my article on federated learning. You can find it here:
What is Federated Machine Learning?

Many AI applications rely on personalization to be useful for a user. With rising AI competition around the globe, we’ve seen many countries enact localization data privacy regulations.These regulations restrict access of personal information for a country’s citizens either by requiring their data to be geographically stored within the country’s borders…
Decoupled DiLoCo is created by enabling the updating process above to happen asynchronously. This is done using four algorithmic components:
Quorum-based synchronization: The outer optimization only waits for K-of-N learners to send their updates before optimizing centrally. This means they don’t wait on all other learners, but only those that are able to reconcile soonest. This makes the system much more robust to learners prone to straggling and errors. This contains the “blast radius” of learner failures by ensuring they don’t impact other learners.
An adaptive grace window: To ensure the outer optimization gets as many inner optimization updates as possible, it will adaptively wait longer for learners to arrive with their updates before completing the outer optimization. This wait time is determined by “slack,” or the amount of time the algorithm computes it can wait without holding up training, minus the amount of time it has already taken to find a quorum of learners. This process ensures the training output isn’t biased toward the lowest latency learners.
Token-weight merging: The synchronizer will keep track of the central learning contribution of each learner based on the number of steps and tokens that learner has trained on. The central model will weigh optimization from each learner based on the number of tokens it has trained on since it last contributed to outer optimization. This keeps merging inner optimization from being overly dominated by low-progress states.
Fragmented, scheduled synchronization: At each outer optimization, only a subset of model weights is reconciled. These subsets are called fragments and are used to avoid large periodic bandwidth spikes. More generally, fragmenting and scheduling helps manage staleness/overwrites under asynchrony and makes communication easier to overlap with compute. Updating fragments also reduces the required peak bandwidth for training.

Practically, Decoupled DiLoCo looks like:
Learners perform inner optimizations. The tokens and step count of each learner are sent asynchronously to the synchronizer so it understands progress.
The syncer maintains a global step count to determine when it’s time to reconcile specific fragments with certain learners (fragmented, scheduled synchronization).
The syncer triggers an update, looking for K-of-M learners based on the metadata received from the first step (quorum-based synchronization).
After reaching K learners, the syncer waits the rest of its slack time for other learners without blocking progress (adaptive grace window).
The syncer pulls and merges the relevant fragment updates using the learners’ step and token count (token-weighted merging) and applies the outer update to produce a new global fragment.
The updated fragment weights are pushed back to learners asynchronously.
This process continues until training is complete.
Google’s Experimentation Findings
Google tested multi-region training runs and simulated infrastructure failures to empirically test the benefits of Decoupled DiLoCo. Here’s a quick summary of what they found:
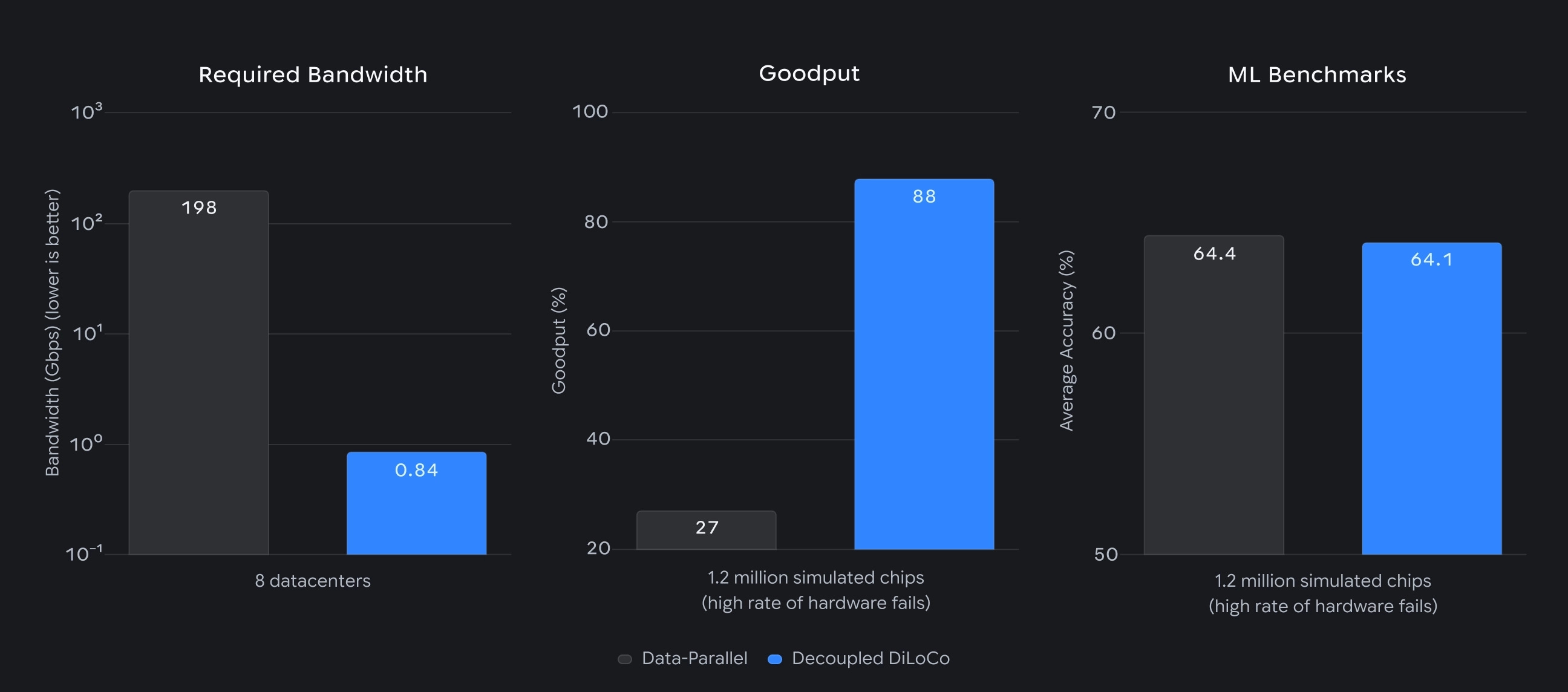
>20× faster vs conventional synchronous training: Training a 12B parameter model across four U.S. regions using 2–5 Gbps connections achieved this speedup due to reduced latency.
Survived learner-unit failures and later reintegrated them: Artificial hardware failures were introduced during training, and Decoupled DiLoCo continued training after losing entire learner units and reintegrated them when they returned online.
Goodput stayed high under failures: They evaluated hardware failures via goodput: 98% goodput at 150k chips and 88% goodput at 1.2M chips.
Downstream quality remained comparable: For a dense 5B model trained on 1T tokens, they show 88% goodput and downstream metrics like Text (Avg) = 68.4 and Vision (Avg) = 54.3, alongside the no-failure baselines.
When is this useful, and when is it not?
As a general rule, Decoupled DiLoCo is most useful for training jobs spanning multiple regions and/or datacenters, especially when availability needs to be increased.
For example, flaky infrastructure can make large-scale jobs impossible. With Decoupled DiLoCo, we can potentially mitigate the large impact of those failures.
Another more interesting potential use case is getting the most out of stranded compute. In datacenters, accelerators are connected in specific topologies, or grids of chips, with high-bandwidth connections between them. This makes it much easier to allocate compute resources based on the size of a training job.
This can also cause compute to become stranded if it isn’t needed for a given training job within its datacenter, but can’t be usefully applied to another application. Decoupled DiLoCo can potentially link those accelerators into training jobs distributed across multiple regions.
If you want to better understand ML infrastructure complexities, check out this overview I wrote a few years ago:
Machine Learning Infrastructure: The Bridge Between Software Engineering and AI

Due to popular demand, here's an overview of machine learning infrastructure (ML infra). The aim of this article isn't to delve into the complexities of ML infra but to provide a straightforward overview, highlighting the differences between machine learning infrastructure and typical software systems. My goal is to make this understandable for all read…
Decoupled DiLoCo isn’t particularly helpful for scenarios where WAN-distributed training isn’t necessary, or for training regimes that require strong consistency. Understanding which training regimes do and don’t tolerate weaker consistency will require more research, and it’s one of the potential limitations of Decoupled DiLoCo.
What are the limitations?
The biggest unknown is whether this method scales to larger training jobs, more (and smaller) distributed learners, other architectures/training processes (i.e., not LLMs), and the other variables that differ between machine learning workloads.
Decoupled DiLoCo also requires infrastructure to complete the synchronization process. Datacenters must be equipped to handle distributed training across regions by incorporating the algorithm described above into the AI infrastructure.
Regardless, Decoupled DiLoCo shows potential promise even if only applied to large-scale LLM pretraining, which takes up most of the AI compute today.
Takeaways
Enabling large-scale, multi-region distributed training opens the door to more cost-effective and resource-efficient large-scale machine learning. It has the potential to fundamentally change LLM pretraining, AI infrastructure requirements, federated learning, and access to AI accelerators.
More work is needed to understand the impact decoupling has on training applications outside of LLM pretraining, to implement this at a wider scale, and to understand how it behaves in practice.
My biggest takeaways:
For infra/platform teams: A huge win in robustness and the ability to pool imperfect capacity across regions/clusters.
For everyone else: There are potential $/token gains via utilization/goodput (less wasted accelerator time) by using Decoupled DiLoCo.
Thanks for reading!
Always be (machine) learning,
Logan