

ICE Has an AI Problem
And a note on surveillance states


The most difficult problem in ML isn’t technical. It’s matching a business problem to an ML solution. You can build a technically impressive system that solves the wrong problem entirely, and it happens more often than most people realize.
This difficulty shows up in data bias, which is frequently discussed. Less discussed is aligning the wrong ML solution to the problem so you don’t actually solve what you set out to. Recent events with ICE and technology in government provide a very real example of this, and there’s a production machine learning lesson to be learned from it.
I’ve been digging into ICE’s primary AI system, and I want to walk through what it does, how it works, and why it fails at its own stated objective. The goal is for you to understand the difficulties of linking ML solutions to business problems and the potential impact of getting it wrong.
The business objective
Understanding the business objective is the most difficult part of machine learning. You need to link ML techniques and data to adequately address the problem, and that’s harder than it sounds.
Part of this is breaking the business objective down into manageable chunks with engineering requirements. An engineering team that wants to automate the detection of fraudulent transactions needs to translate “reduce fraud losses” into specifics: what counts as fraud, what’s an acceptable false positive rate, how fast does detection need to happen, and what systems need to consume the output? Getting any of these wrong means your model might perform well on paper while failing in practice.
The other part is ensuring the ML solution solves the actual problem, not a proxy for it.
This has gone wrong before. Predictive policing systems trained on arrest data instead of actual crime data didn’t predict where crime would happen. They predicted where police already patrolled. Neighborhoods with heavy police presence generated more arrests, which fed back into the model as “high crime areas,” which sent more officers there, which generated more arrests. The system reinforced the existing pattern of enforcement rather than identifying actual criminal activity. The result was a feedback loop that directed resources based on historical policing bias, not public safety need.
To evaluate whether ICE’s AI system falls into the same trap, we need to understand their business objective. We’ll pull it directly from the White House’s own statement about ICE’s objective:
“Many of these aliens unlawfully within the United States present significant threats to national security and public safety, committing vile and heinous acts against innocent Americans... Enforcing our Nation’s immigration laws is critically important to the national security and public safety of the United States.”
The stated goal is to increase public safety by finding illegal aliens who make the US less safe and removing them from the country. Keep this in mind as we move forward.
ELITE: ICE’s primary AI system
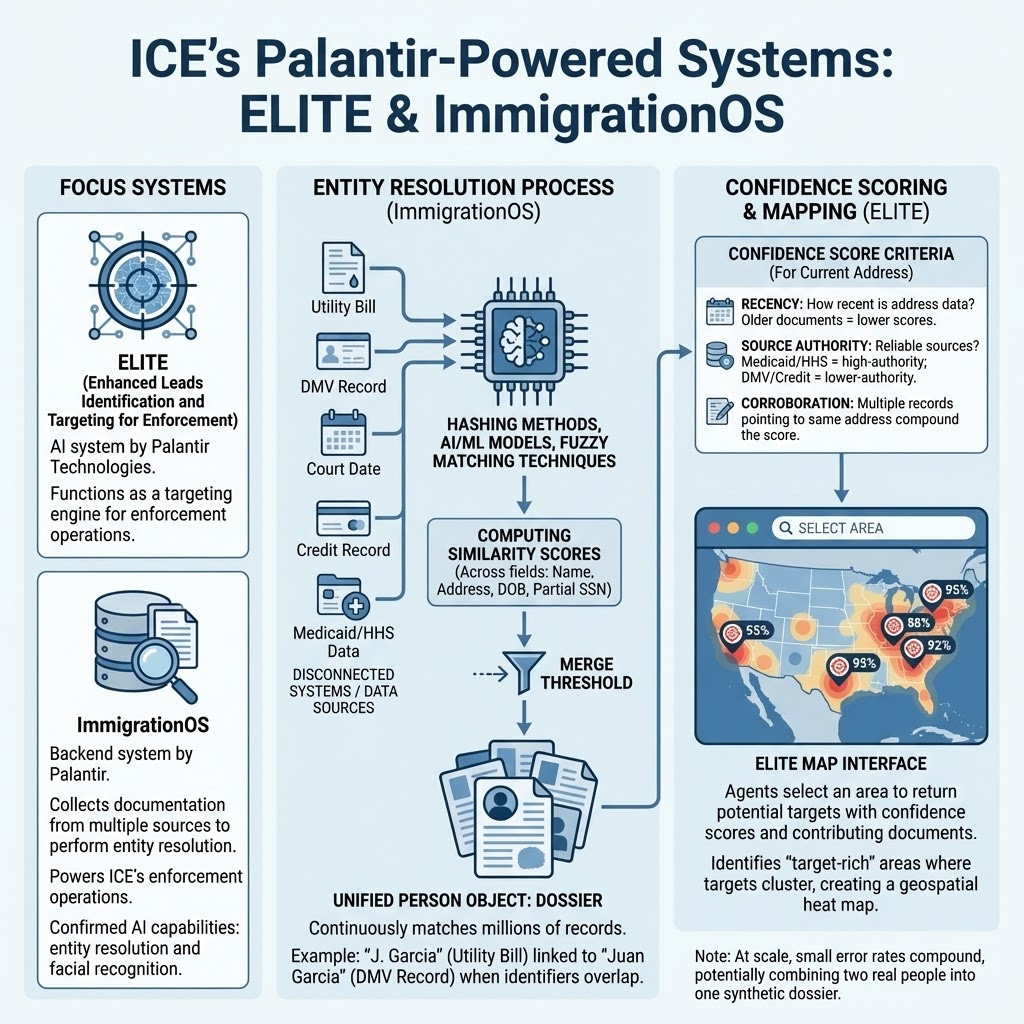
There are multiple systems ICE is using, but we’re going to focus on two. The first is ELITE (Enhanced Leads Identification and Targeting for Enforcement), an AI system developed by Palantir Technologies that functions as a targeting engine. The second is ImmigrationOS, a backend system also developed by Palantir that collects documentation from multiple sources to perform entity resolution. ImmigrationOS directly powers ICE’s enforcement operations, and the DHS AI inventory confirms its AI capabilities for entity resolution and facial recognition.
ELITE aggregates these data sources and uses algorithms to help agents identify, locate, and prioritize individuals for enforcement operations. As one ICE officer revealed in court:
“The app ‘brings up a dossier on each person’ and ‘provides a confidence score on the person’s current address.’ It ‘tells you how many people are living in this area and what’s the likelihood of them actually being there.’”
Palantir’s own documentation describes their entity resolution approach as using “hashing methods and AI/ML models” with “fuzzy matching techniques” to continuously match “millions of records from disconnected systems.” In practice, this means computing similarity scores across fields like name, address, date of birth, and partial SSN, then using a threshold to decide whether two records refer to the same person.
For example, “J. Garcia” on a utility bill gets linked to “Juan Garcia” on a DMV record when enough of those identifiers overlap. The output is a unified person object: a dossier containing everything the system knows about an individual.
Under the hood, entity resolution systems typically use a combination of probabilistic record linkage, TF-IDF or embedding-based similarity measures, and edit distance calculations to compare fields across records. For more technical detail, check out “(Almost) All of Entity Resolution” in Science Advances.
Once an entity is resolved, the system generates a confidence score for where that person might currently live. According to 404 Media’s reporting on ELITE’s user guide, the score is based on both the source of the address and how recent the data is. If a target has multiple recent records (a new electric bill and a recent court date) associated with one address, the confidence score increases.
The score weighs three things:
Recency: How recent is the address data? Collections of older documents get lower scores.
Source authority: Which sources are considered more reliable? Medicaid and HHS data are treated as high-authority. DMV and credit records are considered lower-authority.
Corroboration: Multiple records pointing to the same address compound the score. The more data trails leading to one location, the higher the confidence.
At scale across millions of records from disconnected databases, even small error rates compound. A name misspelling, a shared address between roommates, or a common name in a large city can push the similarity score over the merge threshold and combine two real people into one synthetic dossier.
ELITE’s core feature is a map interface where agents can select an area on a geographical map and return all potential targets within it with their confidence scores and the documents used for entity resolution. ICE agents described this in court testimony as identifying “target-rich” areas where enough targets cluster on the map to make a sweep of that area productive. This essentially creates a geospatial heat map based on the number of targets within a given area and the confidence that they will be there.
Where the data comes from
ImmigrationOS is the technology developed by Palantir that unifies data across federal agencies for AI-powered enforcement, including ELITE.
ICE and Palantir don’t publicly share specifics about their data sources and system functionality. What we know comes from FOIA requests by immigrant legal rights group Just Futures Law, official data sharing agreements, leaked documents, and investigative journalism.
The data feeding this system comes from several sources:
Medicaid enrollment information: Visit dates, addresses, and ethnic information, shared via a formal agreement between CMS and DHS.
Thomson Reuters CLEAR: Utility bills, credit report headers, and vehicle insurance records. ICE potentially paid millions in costs for this commercial data.
Federal records: DMV records, student and F-1 visa information, border crossing records, biometrics from previous arrests or encounters, and license plate reader data.
ICE argues this is legal under 8 U.S.C. § 1360(b) of the Immigration and Nationality Act, which states that “any information in any records kept by any department or agency of the government as to the identity and location of aliens in the US shall be made available to” immigration authorities. However, legal scholars have questioned whether this statute authorizes bulk data sharing for algorithmic targeting, which is a use case Congress likely didn’t envision when the law was written.
One key to ImmigrationOS and ELITE working so well is the inclusion of Medicaid data. This data tends to be accurate and recent, which boosts confidence scores significantly.
Think about who generates Medicaid data. It’s people going to the doctor, getting their kids vaccinated, and seeking preventive care. It’s people participating in the healthcare system and leaving a trail of documentation behind.
The same logic applies to other sources. Utility bills are generated by people who pay their bills. Credit records are generated by people who have credit. Vehicle insurance records are generated by people who insure their cars.
The data that feeds this AI system is overwhelmingly generated by people who are integrated into society and following its rules. This is a textbook example of selection bias: the model can only see people who leave data trails, and leaving data trails is correlated with being a functioning member of society, not with being a threat to public safety.
What these systems actually do for ICE
Now that we understand how the system works, let’s evaluate whether it achieves the business objective: find and remove people who are “threats to national security and public safety.”
“ELITE’s confidence scoring is less about establishing certainty than it is about guiding deployment. The system allows ICE to decide where to apply enforcement pressure without needing to test the reliability of its data before a judge.”
In other words, the system is identifying areas where agents can find the most people to arrest with the least effort. To illustrate how this plays out, consider two hypothetical targets:
Person A: Has lived at the same address for five years, pays utility bills, has a Medicaid record from last month, and drives a registered and insured car. ELITE confidence score: 95%. Time to arrest: a few hours.
Person B: Uses burner phones, moves frequently, works cash-only jobs, avoids all government systems, and performs illegal actions. ELITE confidence score: 12%. Time to arrest: weeks of active surveillance.
The system mechanically pushes agents toward Person A because that’s what efficiency optimization does. It finds the easiest targets instead of the most dangerous ones.
This is structurally the same problem as predictive policing. Just as those systems measured where police already patrolled rather than where crime actually happened, ELITE measures where data trails exist rather than where threats to public safety exist. In both cases, the system optimizes for a proxy metric (arrests, data density) rather than the actual objective (reducing crime, improving public safety). The result is a feedback loop: the system directs resources toward easy-to-find individuals, those individuals get arrested, and the arrest numbers create the appearance of a productive system while the actual problem goes unaddressed.
This creates several compounding issues. First, ICE has finite resources. Every hour spent on Person A is an hour not spent on Person B. Second, the system optimizes for volume over impact, and finding the most targets is not the same as finding the most important ones. Third, the appearance of productivity masks the failure to achieve the stated objective.
The system makes bias worse over time
If someone knows their medical records can be used to locate them for deportation, they’re less likely to go to the doctor. This isn’t speculation. It’s a predictable consequence of weaponizing healthcare data for enforcement. The same logic applies to every data source in the system: utility bills, credit records, vehicle insurance. When participation in society becomes a liability, people stop participating.
This creates a feedback loop that compounds the selection bias. As people who hear the warnings drop out of healthcare and other systems, they stop generating the data trails ELITE relies on. The people who remain visible to the system are the ones who haven’t gotten the message yet, or the ones who are too integrated to disappear. The model’s pool of targets gets progressively less correlated with actual threats over time, not more.
It also creates a public health risk that affects citizens. Diseases don’t check immigration status. An untreated communicable illness in someone too afraid to visit a hospital is a risk to everyone around them. GAO data shows U.S. citizens and green card holders have already been detained during these operations, so the consequences of this system aren’t limited to its intended targets.
Counterarguments
To be fair, there are reasonable counterarguments to make here.
Is this more efficient than what ICE was previously doing? Probably. Compared to manual investigations with no data aggregation, a system like ELITE is a meaningful upgrade in capability. There’s value in having a centralized system rather than agents manually cross-referencing records from dozens of separate databases.
There’s also the argument that regardless of who the system catches, all undocumented immigrants are technically in violation of immigration law. From that perspective, it doesn’t matter whether the system finds Person A or Person B, because both are here illegally.
These are valid points. However, they don’t change the underlying ML problem. The stated objective isn’t “deport as many people as possible as efficiently as possible.” It’s to keep the country safe from people who present “significant threats to national security and public safety.”
When the AI system is structurally biased toward finding integrated, low-risk individuals instead of dangerous ones, it fails at its stated objective regardless of how many people it processes. Incorrectly applied AI doesn’t just fail to help. It actively makes ICE’s job harder. When the system points agents toward low-risk individuals who happen to leave data trails, it burns limited resources on people who were never a threat. Every wrongful detention of a U.S. citizen or green card holder generates legal challenges, public backlash, and erosion of community cooperation that makes future investigations more difficult. The algorithm creates the illusion of productivity while pulling agents further from their actual mission.
The surveillance infrastructure required to power it affects everyone, not just its intended targets, as seen with the Medicaid example. Communities stop cooperating with law enforcement entirely when they see their neighbors swept up in algorithmic dragnets. Healthcare systems lose patients who are too afraid to generate the medical records that feed this machine. Entity resolution errors merge innocent people’s data into dossiers that trigger enforcement actions against the wrong person.
These are the predictable consequences of building a surveillance and enforcement system on data that measures the wrong thing.
A note on surveillance states
Most conversations about the dangers of surveillance states focus on privacy, security, and infringement of rights. All of those are important, but there’s another angle worth considering: the technology itself is prone to exactly the kind of failure I’ve been describing throughout this article.
A surveillance state at modern scale requires AI to function. The volume of data generated by monitoring hundreds of millions of people is far beyond what human analysts can process. AI becomes the tool that makes mass surveillance operationally feasible.
This creates a feedback loop. Better AI requires more data, and a surveillance system run by AI generates exactly that data, which feeds back into making the AI more capable, which justifies expanding the surveillance further.
The problem is what we’ve already covered in this article: it is remarkably easy for AI-powered systems to optimize for the wrong thing or embed bias in ways that aren’t obvious until the damage is done. ELITE is a clear example. It was built to find threats to public safety and instead systematically targets the least threatening people because that’s where the data is.
When this kind of failure happens at the scale of a surveillance state, the consequences aren’t abstract. Incorrect AI usage has directly resulted in the detention of U.S. citizens, which is the opposite of what these systems claim to achieve. If the goal is safety, a system that consistently misdirects enforcement effort is arguably worse than no system at all.
Surveillance states aren’t just dangerous because of what they monitor. They’re dangerous because the technology powering them is far less reliable than the people deploying it seem to understand.
Always be (machine) learning,
Logan
I think your approach of comparing the technical system against the stated goals of the agency is brilliant. No politics, just a lucid project evaluation. Really well done!
Thank you for the info, now I see why it was ordered, that people can only go to family doctors where they live, and threaten the doctors.
Hungary.